近年来,随着图结构数据场景的使用越来越广泛,图机器学习也受到了非常多的关注。如今,动辄亿级节点或者百亿级边的大规模数据挑战正向社会袭来,可面向超大规模图谱的图机器学习研究更是少之又少。
来自OPPO研究院数据智能研究部的拓扑实验室成员为此集结,在KDD Cup 2021中的MAG240M-LSC比赛中提出了能轻巧应对超大规模异构网络的MPLP方案,此方案不仅简化了模型复杂度,而且具有很高的扩展性。该项技术方案最终获得了第四名的好成绩。
比赛相关技术文档和代码已经开源:
https://github.com/qypeng-ustc/mplp
由于图结构数据在各个场景中得到越来越多的应用,包括社交网络、推荐搜索、知识图谱、医药研发、量子物理等,图机器学习受到了非常多的关注。另一方面,动辄亿级节点或者百亿级边的大规模图数据正逐渐带来新的挑战,而目前面向超大规模图谱的图机器学习研究较少。
2021年,斯坦福大学等相关的团队在 KDD Cup 2021开展了大规模图网络比赛,直击当前图学习研究的痛点。一方面 KDD (Knowledge Discovery and Data Mining)作为世界数据挖掘领域最高级别的学术会议,吸引了全球顶尖研究机构前来展现“武功”,另一方面组织者斯坦福大学的Jure Leskovec领导的OGB团队作为图神经网络权威,其赛题质量自然也能够保证。
比赛网址:
https://ogb.stanford.edu/kddcup2021/
高质量的赛题加上优秀的竞争对手,角逐出来的技术方案备受业界关注。在节点预测赛道中,OPPO 研究院数据智能研究部的拓扑实验室获得了第四名的成绩。如果细究其解决方案,可以发现OPPO提出的MPLP模型更加轻巧,计算开销更小,也更具扩展性。
1
赛题介绍
此次比赛的全称是“OGB Large-Scale Challenge”,由 KDD Cup 2021和Open Graph Benchmark 官方联合举办,全球共有500多个队伍参赛。
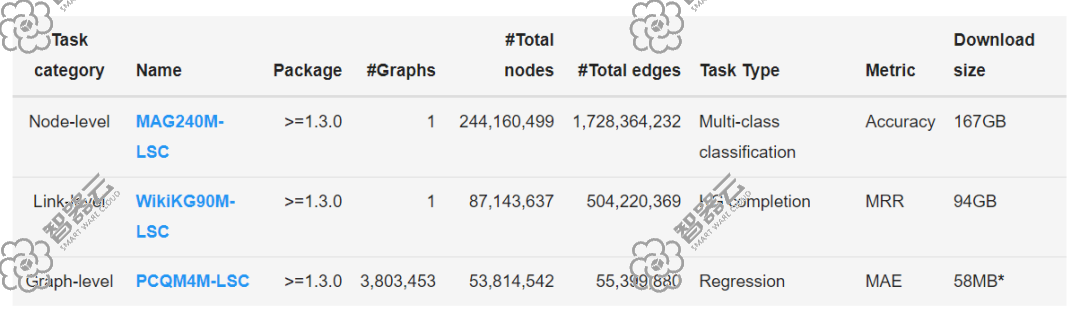
比赛共发布三个数据集,分别对应三个赛道。其中MAG240M-LSC是一个异构的学术图,其任务是预测位于异构图中的论文的学科类别;WikiKG90M-LSC是一个知识图谱,其任务是估算缺少的三元组;PCQM4M-LSC是量子化学数据集,其任务是预测给定分子的重要分子特性。
对于每个数据集,赛事的组织者都经过精心的设计,以求参赛者在任务上提交的算法能够直接影响相应的应用。
三个数据集以及任务比较
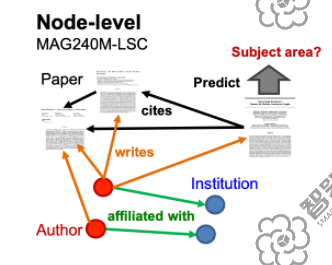
其中节点预测赛道中的MAG240M-LSC 数据集是从Microsoft Academic Graph (MAG)中提取出的异构学术网络数据, 总节点数 244,160,499,总边数1,728,364,232,包含有1.2亿paper、1.2亿author、2.6万 institution三种类型节点以及cites、writes等边类型,且paper的类别多达153种,压缩的原始数据集大小167GB,是这次比赛中数据量最大、结构最复杂的任务。
基于以上,赛事主办方给参赛者的任务是:设计模型,预测论文所属的类别,准确率越高越好。比赛要求参赛者用2018年及之前的论文作为训练集,2019年发表的论文作为验证集,2020年的论文作为测试集。
此外,比赛仅有一次最终提交机会,也在某种程度上增加了任务难度。
3月15日~6月8日,经过接近三个月的激烈竞争,主办方根据准确率最终选出了六只优胜队伍,其中第一名的准确率是0.7549,第6名的准确率为0.7353,相差仅不到0.02。可以看出,顶级选手们的解决方案都非常优秀,在准确率方面差距并不大,只有综合考虑计算开销、模型复杂度才能看出谁能最大程度的适用工业场景。
排名第四的OPPO团队提出的MPLP模型在所有靠前的解决方案中“最为轻巧”,算法的两个独立部分来看:
对训练和预测的节点,将标签和特征通过设定的元路径(Metapath)进行聚合,可以实现高效的特征预计算;
训练一个多层MLP模型,模型参数不到百万。
因此,模型的采样仅涉及到训练和预测样本的2-hop邻居,而且可以通过并行加速,标签类特征预生成部分仅需要2小时20分钟(12个CPU),MLP模型完全放到GPU中训练和推理,200个epoch只需要20分钟。
而R-UniMP和APPNP等GNN模型,在单机多卡加速的情况下,单个模型训练仍需要至少需要24小时。
在准确率方面和其他队伍存在差距的原因是什么呢?笔者通过与拓扑实验室团队的沟通中得知:
1、MPLP在特征和标签信息提取方面选择非常简单的聚合方式,不同于其他参赛队伍选择较复杂的图卷积的做法;
2、由于时间有限,最终提交的模型只考虑了部分元路径,同时考虑到过拟合问题,团队基于对数据的理解和训练效率考虑,删除了部分元路径;
3、MPLP非常简单,在大家都考虑到特征传递和标签传播的情况下,表达能力略有不足。
换句话说,OPPO用微弱的准确率下降,换来了模型的简洁性和计算开销的节约。
2
MPLP模型
MPLP模型,全称 “Metapath-based Label Propagation”,主要思路是通过结合不同异构元路径( Metapath,MP)下的标签传播生成的信息输出到下游分类器。
其中 H_emb为通过模型获得的图嵌入特征,H_pk·X表示在第K个MP上进行特征 X传播,Θ_k为参数(做维度变换用)。在MPLP框架下,特征和标签在不同的MP下分别进行传播,之后将结果聚合起来输送到下游分类模型中。
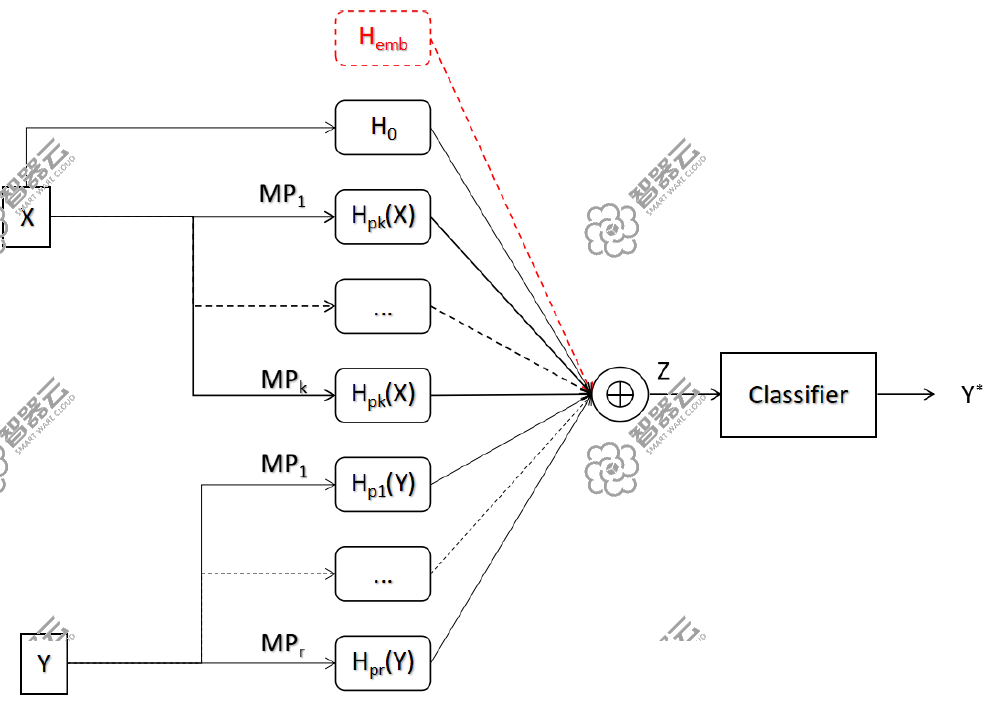
模型架构
模型训练分两步,第一步是在多种不同的MP上进⾏标签传播,包括paper-writed_by-author-writes-paper、paper-cited_by-paper-cites-paper等,获取不同MP下的标签分布信息作为节点当前MP下的特征;第二步将所有MP获得的特征分别做空间映射后结合起来,输入到下游分类器进行分类预测。
如何将MPLP运用到节点预测任务中?由于比赛数据规模巨大,且数据中论文的主题分布随时间演化,加上论文分布极其不均匀,部分主题的论文数量只有几十篇,而另外一些主题的论文数达到几万篇。
针对上述三个难点,MPLP可以在不同的MP上预先进行标签传播,类似于SIGN和NARS方法,所以在规模和效率上具有天然的优势;对于标签分布随着时间演化问题,团队采用了类似迁移学习微调方法;
对于类别不均衡,团队定义了标签权重方法。其中cnt_2018 是维度为N_class=153 的一维向量,其每一位表示在2018年相应主题的论文数量,超参α 设置为5。
MPLP模型下吸收不同特征的实验结果
上图展示了在MPLP模型下吸收不同特征的实验结果,Valid Acc (weight)表示在当前模型中加入类别weight的结果,括号内为未进行finetune。针对不同的模型,label代表不同MP下标签 Y传播的信息,feat 代表不同MP下特征X传播的信息,R-GAT和 LINE-2nd表示相应预训练模型的嵌入特征。考虑到模型复杂度和准确率表现,团队最终采用了MPLP (label + R-GAT) 方法。
与基准比较结果
为了抑制过拟合,团队在训练中采用了5-fold 交叉验证的方法,并进一步的采样8个不同的随机种子来初始化模型,最终的预测结果来自40个模型的ensemble。并且,通过将数据集往前推1年,将2018年数据作为验证集,将2019年数据作为测试集,验证了这种集成方式的有效性。MPLP和其他较强的baseline比较结果如上图所示。
3
为什么参加这个比赛?
KDD Cup 全称为国际知识发现和数据挖掘竞赛,自1997年开始,由 ACM 协会 SIGKDD 分会每年举办一次,目前是全球数据挖掘领域最有影响力的赛事,其所设比赛题目具有相当高的实际意义和商业价值。
OPPO拓扑实验室成立仅一年,专门从事图学习研究。目前在团队规模、技术积累、研发投入等方面仍处于初级阶段。拓扑实验室表示,这种将深度学习和图论相结合处理图结构数据的方法,既保留了深度学习的优势,又拓展了其应用边界,与当前OPPO面向的落地场景十分契合。
通过这场赛事,OPPO拓扑实验室证明了自己在图网络方面的研究成果,也首次在国际平台展现了不俗的技术实力。其实从更大范围来讲,这场比赛不仅对于所有参赛机构来说是更加公平可信的竞技场,也是引导学术界走向超大规模图谱研究的契机。
ImageNet 毋庸置疑推动了计算机视觉的发展,而OGB-LSC已经展现了图学习发展的一个趋势:技术方向从“真空”学术研究转向实际工业场景。毕竟,任何前沿技术研发都是为产业化应用服务的。在学术界,虽然图神经网络的论文越来越多,但这些实验方法与现实场景的应用仍相距甚远,很多论文所使用的实验数据,与工业界真实场景的数据差距非常大,导致很多实验效果在现实场景中无法复现。
拓扑实验室团队表示,这次比赛所使用的三个数据集是基于真实场景的超大规模图谱数据,具有相当的权威性,通过这些数据所获得的实验结果和成绩也更能让人信服。
4
OPPO为何看中“图网络”?
深度学习方法被应用在提取欧氏空间数据的特征方面取得了巨大的成功,但许多实际应用场景中的数据是从非欧式空间生成的,传统的深度学习方法在处理非欧式空间数据上的表现却仍难以使人满意。
最近几年,研究人员结合传统深度学习和图论,设计了用于处理图数据的图学习技术,并进入一个爆发式的增长阶段。通过学术界和工业界的共同努力,图学习技术已经被成功应用到安全风控、搜索推荐、姿态估计和知识图谱等实际应用场景,并达到一定的成熟度;同时研究人员也在探索更多的应用场景,比如:因果推理。通过对新技术的长期探索和应用,帮助产品和服务提升用户体验,对OPPO至关重要,也是OPPO品牌信仰“科技为人,以善天下”的内在诠释。
值得一提的是,图算法呈现的“结构化知识+跨领域”的特征,正好与清华大学的张钹院士提出的以“知识+数据双轮驱动”为核心的第三代人工智能不谋而合。
作为最具潜力的新型技术路线之一,图网络除了基础理论方面的创新外,更重要的是拓展更多的应用场景。不过,二者的关系是相辅相成的——有了理论上的突破,图神经网络的效果才能更强大。未来拓扑实验室将面向安全风控、搜索推荐等现实场景在图算法研究方面投入更多,加速致善式创新。